Chapter 2 Linear Regression
You probably learned something about linear regression in a previous course. Here, we briefly review the main concepts of simple linear regression and quickly expand our tool box to multiple regression (with both quantitative and categorical predictors).
2.1 Data
We will consider a small dataset from an article by J.S. Martin and colleagues, titled Facial width-to-height ratio is associated with agonistic and affiliative dominance in bonobos (Pan paniscus)
Notes: variable fWHR is the facial width-height ratio and AssR is the Assertiveness score of affiliative dominance. normDS is another dominance score. A few figures of the data are below - we will do some more exploration together.
## Observations: 117
## Variables: 8
## $ Name <fct> Zuani, Zuani, Zorba, Zorba, Zorba, Zomi, Zomi, Zamba, Z...
## $ Group <fct> Apenheul, Apenheul, Wilhelma, Wilhelma, Wilhelma, Frank...
## $ Sex <fct> Female, Female, Male, Male, Male, Female, Female, Male,...
## $ Age <int> 22, 22, 34, 34, 34, 15, 15, 14, 14, 14, 18, 18, 18, 18,...
## $ fWHR <dbl> 1.48, 1.32, 1.58, 1.48, 1.39, 1.34, 1.26, 1.88, 1.49, 1...
## $ AssR <dbl> 5.36, 5.36, 2.36, 2.36, 2.36, 3.92, 3.92, 4.74, 4.74, 4...
## $ normDS <dbl> 1.43, 1.43, 2.34, 2.34, 2.34, 3.09, 3.09, 3.04, 3.04, 3...
## $ weight <dbl> 24.0, 24.0, NA, NA, NA, NA, NA, 41.6, 41.6, 41.6, 38.0,...

2.2 Simple linear regression, Residuals & Least squares
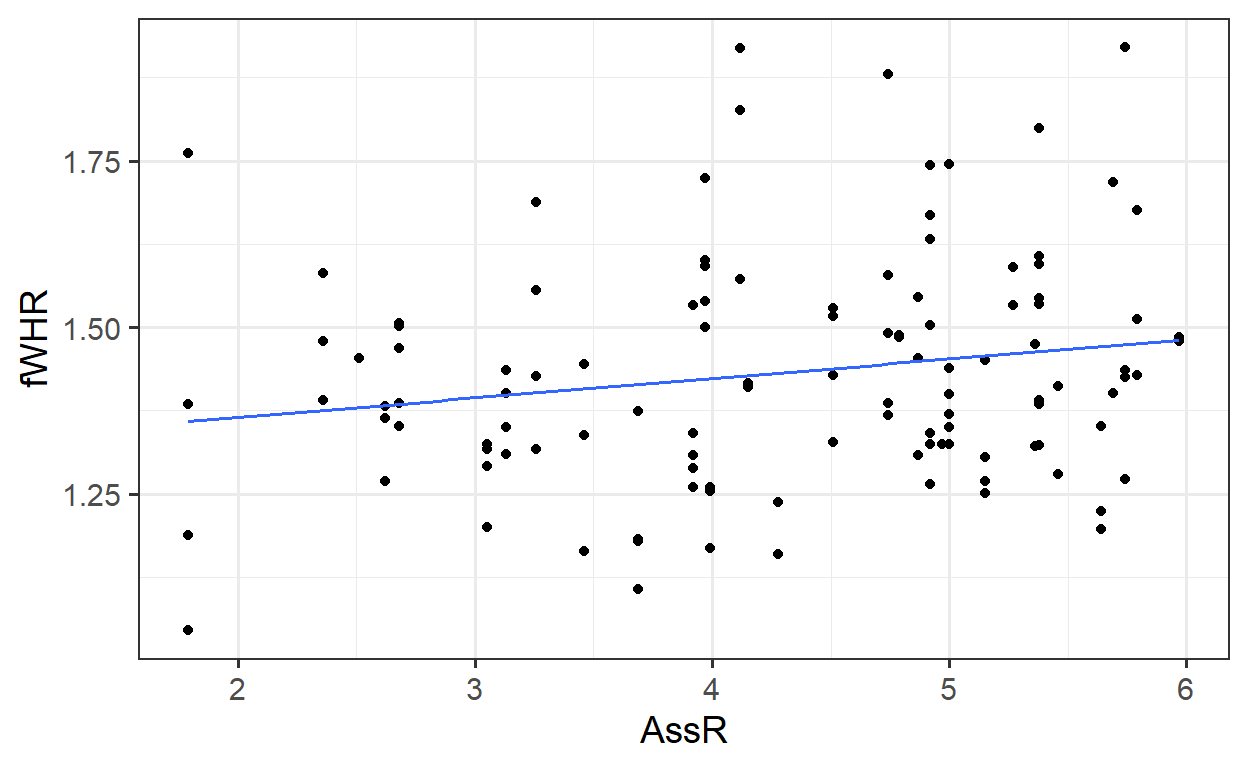
First, let’s review and consider a simple (one-predictor) linear regression model. Fit the model
Extract the slope and intercept values:
## (Intercept) AssR
## 1.3069 0.0292Add the regression line to the plot:
##
## Call:
## lm(formula = fWHR ~ AssR, data = bonobos)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.3132 -0.1137 -0.0124 0.0901 0.4924
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.3069 0.0628 20.80 <2e-16 ***
## AssR 0.0292 0.0142 2.06 0.042 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.169 on 115 degrees of freedom
## Multiple R-squared: 0.0354, Adjusted R-squared: 0.027
## F-statistic: 4.22 on 1 and 115 DF, p-value: 0.04212.2.1 Using lm() to fit a linear regression in R
2.2.2 Equation of the fitted regression line
2.3 Multiple regression
Rarely does our response variable really depend on only one predictor. Can we improve the model by adding more predictors?
## (Intercept) AssR weight
## 0.94479 0.03989 0.00864
2.3.1 Is it really better?
How do we know if the model with more predictors is “better”? (For a more detailed answer, wait about a week…) But before we can define a “beter” model: how did R find the “best” intercept and slopes?
2.3.2 Regression residuals = “errors”
2.3.3 Computing Predictions
Use the regression equation to compute predicted values for the three data points below:
## fWHR AssR weight
## 8 1.88 4.74 41.6
## 25 1.80 5.38 50.6
## 41 1.59 3.97 NA
## 65 1.55 4.87 38.5
2.4 Predictors with two categories
## (Intercept) AssR weight SexMale
## 1.06542 0.05844 0.00226 0.12848How does the model incorporate this covariate mathematically?
2.4.1 Predictors with more categories

## (Intercept) AssR weight SexMale
## 1.00773 0.06436 0.00346 0.12485
## GroupFrankfurt GroupPlanckendael GroupTwycross GroupWilhelma
## 0.03743 -0.00846 -0.11291 0.01119
## GroupWuppertal
## -0.00436How does the model incorporate this covariate mathematically?
2.5 Returning to the R Model Summary
There are several bits of information you should be able to extract from the summary() output R produces on a fitted linear regression model:
\(\beta\)s, Coefficient Estimates
\(\sigma\), labeled “residual standard error”
\(R^2\) (adjusted)
##
## Call:
## lm(formula = fWHR ~ AssR + weight + Sex + Group, data = bonobos)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.3829 -0.0949 -0.0264 0.0720 0.4846
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 1.00773 0.21758 4.63 2e-05 ***
## AssR 0.06436 0.02116 3.04 0.0035 **
## weight 0.00346 0.00555 0.62 0.5353
## SexMale 0.12485 0.05928 2.11 0.0394 *
## GroupFrankfurt 0.03743 0.07489 0.50 0.6191
## GroupPlanckendael -0.00846 0.07541 -0.11 0.9110
## GroupTwycross -0.11291 0.07478 -1.51 0.1364
## GroupWilhelma 0.01119 0.08554 0.13 0.8964
## GroupWuppertal -0.00436 0.07129 -0.06 0.9514
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.169 on 59 degrees of freedom
## (49 observations deleted due to missingness)
## Multiple R-squared: 0.252, Adjusted R-squared: 0.15
## F-statistic: 2.48 on 8 and 59 DF, p-value: 0.02172.6 Predictions from the model
2.6.1 By Hand
The equation for the fitted model above is:
\[ y = \beta_0 + \beta_1x_1 + \beta_2x_2 + \beta_3I_{Male} + \beta_4I_{Frankfurt} + \beta_5I_{Planckendael} + \beta_6I_{Twycross} + \beta_7I_{Wilhelma} + \beta_7I_{Wuppertal} + \epsilon\]
where
- \(y =\)
- \(\beta_0=\)
- \(x_1=\)
- \(x_2=\)
- \(\beta_1, \beta_2, \beta_3 ...\) are:
- \(I_{Male} =\)
- \(I_{Frankfurt} =\)
- \(I_{Planckendael} =\) , etc.
- \(\epsilon=\)
2.6.1.1 Comprehension check:
What is the expected fWHR (according to this model) for a 30 kg female bonobo at the Wilhelma zoo?
2.6.2 Prediction Plots in R
We can ask R to compute predictions for all the data points in the real dataset.
## Error: Column `preds` must be length 117 (the number of rows) or one, not 68Wait, what? This error is because the lm() function removes rows containing missing values from the dataset, so it computes only 68 residuals (for the complete cases in the data). This doesn’t match the 117 rows in the original data. We can solve the problem by omitting rows with missing values first. To be safe, we first select only the variables we need, so we don’t omit rows based on missing values in unused variables.
b2 <- bonobos %>%
dplyr::select(fWHR, weight, AssR, Sex, Group) %>%
na.omit() %>%
mutate(preds = predict(mlr3))We have a full set of predictions!
But if we plot these predictions on a scatter plot of fWHR as a function of AssR, we do not get a straight line, because the predictions are also impacted by varying values of weight, Sex, and Group:
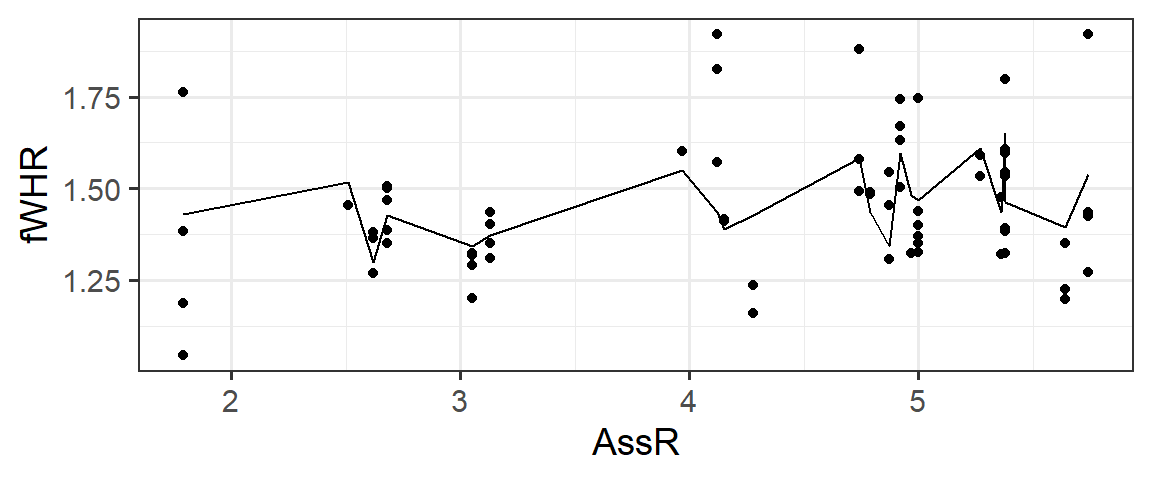
But…we would really like a straight line that helps us visualize the meaning of the \(\beta\) (slope coefficient) for AssR. We can make predictions for a hypothetical dataset, in which AssR varies over a reasonable range, but the other predictors stay constant. This lets us see how AssR (and only AssR) affects the response, without contributions from other predictors. In choosing the values to include in hypothetical dataset, we often choose to hold variables constant at their most common or median values, but not blindly: also, avoid impossible or implausible variable combinations (for example, specifying that a person lives in the state of Michigan but the city of Chicago, or that they are a 5-year-old person with 4 children). In this case, to match the figures in the published paper, we are also going to vary the Sex - but generally you’d only allow one predictor to vary.
fake_data <- expand.grid(AssR = seq(from=1.8, to=5.7, by=0.05),
weight = 38.5,
Sex = c('Female', 'Male'),
Group = 'Wuppertal')
fake_data <- fake_data %>%
mutate(preds = predict(mlr3, newdata = fake_data))
gf_line(preds ~ AssR, color = ~Sex, data=fake_data) %>% gf_labs(y='Predicted\nfWHR')
2.6.2.1 Comprehension checks:
- Should we overlay prediction-plot line(s) on the data scatter plot?
- How do you think the plot would look if we changed the constant predictor values?
- What is missing from this picture?

2.7 Why are we doing this again?
Why make prediction plots?
2.8 Shortcut Method - With Uncertainty
We saw before that pred_plot() makes it very easy for us to generate prediction plots showing what a (multiple regression) model says about the relationship between the response and one of the predictors:

Note the custom axis label - otherwise you get a long, unwieldy default “Predictions from fitted model”

They look nice! But they should raise two questions:
Uncertainty:
Fixed values:
| Name | Group | Sex | Age | fWHR | AssR | normDS | weight | three | pt_size |
|---|---|---|---|---|---|---|---|---|---|
| Eja | Twycross | Female | 21 | 1.412 | 4.51 | 2.368 | 40 | no | 1 |
2.9 DIY Method
2.9.1 Creating a hypothetical dataset
We would like to create a hypothetical dataset where one predictor variable varies, and all the rest stay fixed. Let’s choose AssR. We use expand.grid():
fake_data <- expand.grid(AssR = seq(from=1.8, to=5.7, by=0.05),
weight = 40,
Sex = 'Female',
Group = 'Twycross')
glimpse(fake_data)## Observations: 79
## Variables: 4
## $ AssR <dbl> 1.80, 1.85, 1.90, 1.95, 2.00, 2.05, 2.10, 2.15, 2.20, 2...
## $ weight <dbl> 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40,...
## $ Sex <fct> Female, Female, Female, Female, Female, Female, Female,...
## $ Group <fct> Twycross, Twycross, Twycross, Twycross, Twycross, Twycr...Now, make predictions for our fake data.
preds <- predict(mlr3, newdata = fake_data, se.fit = TRUE)
fake_data <- fake_data %>%
mutate(fitted = preds$fit,
se.fit = preds$se.fit)
glimpse(fake_data)## Observations: 79
## Variables: 6
## $ AssR <dbl> 1.80, 1.85, 1.90, 1.95, 2.00, 2.05, 2.10, 2.15, 2.20, 2...
## $ weight <dbl> 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40,...
## $ Sex <fct> Female, Female, Female, Female, Female, Female, Female,...
## $ Group <fct> Twycross, Twycross, Twycross, Twycross, Twycross, Twycr...
## $ fitted <dbl> 1.15, 1.15, 1.16, 1.16, 1.16, 1.17, 1.17, 1.17, 1.17, 1...
## $ se.fit <dbl> 0.0835, 0.0827, 0.0819, 0.0811, 0.0803, 0.0795, 0.0788,...How do we go from standard errors to confidence intervals? We can either do this before plotting, or while plotting. To do it before and add the results to the hypothetical dataset:
fake_data <- fake_data %>%
mutate(CI_lower = fitted - 1.96*se.fit,
CI_upper = fitted + 1.96*se.fit)
glimpse(fake_data)## Observations: 79
## Variables: 8
## $ AssR <dbl> 1.80, 1.85, 1.90, 1.95, 2.00, 2.05, 2.10, 2.15, 2.20,...
## $ weight <dbl> 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 40, 4...
## $ Sex <fct> Female, Female, Female, Female, Female, Female, Femal...
## $ Group <fct> Twycross, Twycross, Twycross, Twycross, Twycross, Twy...
## $ fitted <dbl> 1.15, 1.15, 1.16, 1.16, 1.16, 1.17, 1.17, 1.17, 1.17,...
## $ se.fit <dbl> 0.0835, 0.0827, 0.0819, 0.0811, 0.0803, 0.0795, 0.078...
## $ CI_lower <dbl> 0.985, 0.990, 0.995, 1.000, 1.005, 1.009, 1.014, 1.01...
## $ CI_upper <dbl> 1.31, 1.31, 1.32, 1.32, 1.32, 1.32, 1.32, 1.32, 1.33,...2.9.2 Making the plot
Now, we just need to plot!
gf_line(fitted ~ AssR, data=fake_data) %>%
gf_labs(y='Predicted\nfWHR') %>%
gf_ribbon(CI_lower + CI_upper ~ AssR, data = fake_data)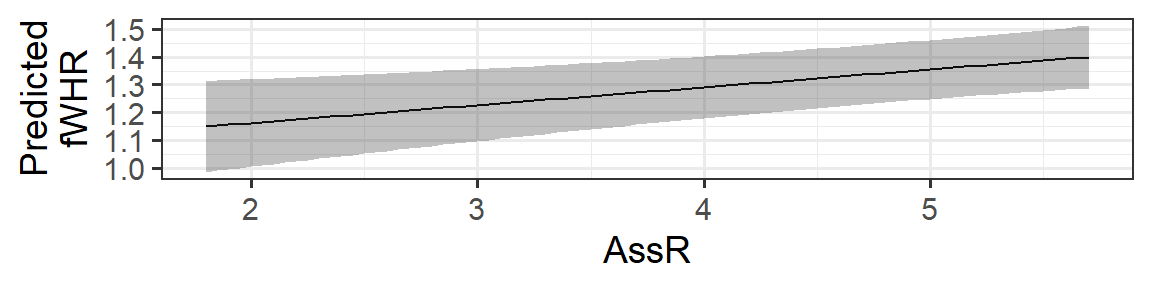
If we wanted to figure out the CI bounds while plotting, we could calculate them on the fly like this:
gf_line(fitted ~ AssR, data=fake_data) %>%
gf_labs(y='Predicted\nfWHR') %>%
gf_ribbon((fitted - 1.96*se.fit ) + (fitted + 1.96*se.fit) ~ AssR,
data = fake_data)(which will look just the same).
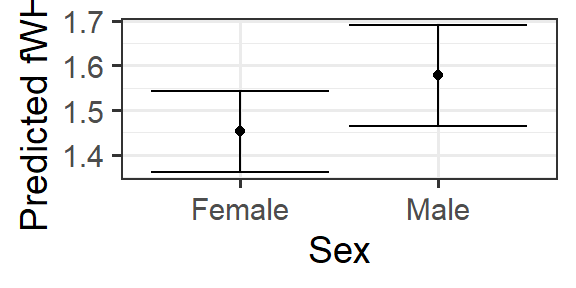
2.9.3 Categorical predictors
What will be different if the predictor of interest is categorical?
hypothetical data:
plot:
fake_sex_data <- expand.grid(AssR = 4.51,
weight = 40,
Sex = c('Male', 'Female'),
Group = 'Twycross')
preds <- predict(mlr3, newdata = fake_sex_data, se.fit = TRUE)
fake_sex_data <- fake_sex_data %>%
mutate(fitted = preds$fit,
se.fit = preds$se.fit)
gf_point(fitted ~ Sex, data=fake_sex_data) %>%
gf_labs(y='Predicted fWHR') %>%
gf_errorbar((fitted - 1.96*se.fit ) + (fitted + 1.96*se.fit) ~ Sex,
data = fake_sex_data)